
1.03 + krótkie podsumowanie

Wpis dodano ·
2225 wyświetleń
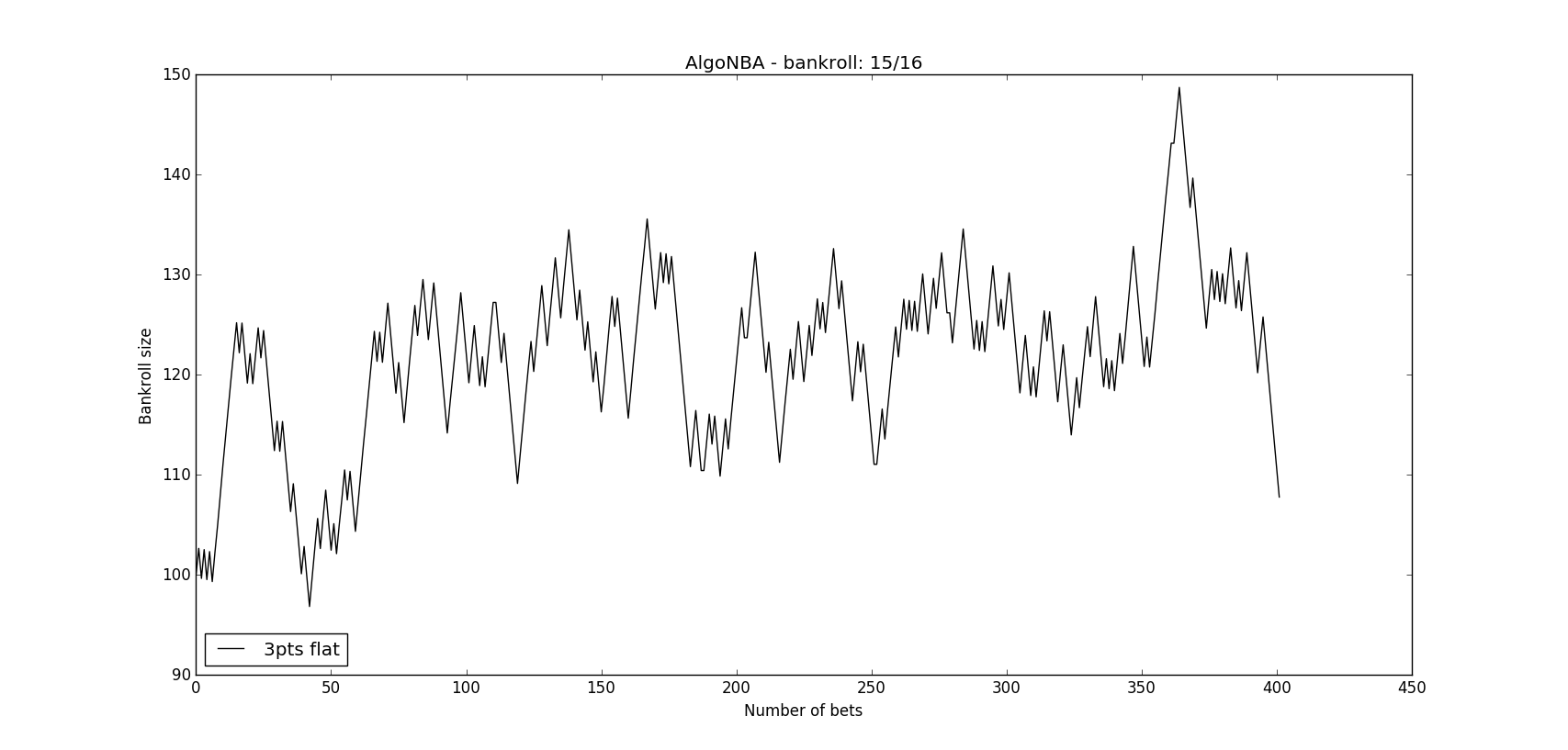
Po 401 betach zysk wynosi +7.78pts, yield 6‰.
 +12.5 @ 1.934
+12.5 @ 1.934
 +5.5 @ 2.020
+5.5 @ 2.020
 +5.5 @ 1.909
+5.5 @ 1.909
 +5.5 @ 1.925
+5.5 @ 1.925
 +10 @ 1.884
+10 @ 1.884
 +2 @ 1.943
+2 @ 1.943
TOTAL P/L GRAPH:
- lostdesper zareagował na to
-
 1
1
4 komentarze
Promowane komentarze